DB에서 쿼리 최적화(Query Optimization)는 성능을 결정짓는 핵심 요소 중 하나이다.
간단히 Optimizer는 사용자가 작성한 SQL 쿼리를 분석하여 실행 비용이 가장 낮은(또는 상대적으로 효율적인) 실행 계획을 선택하는 역할을 맡는다.
MySQL Optimizer의 내부 구조와 동작 원리를 알아보고, 쿼리가 어떻게 최적화되어 실행 계획으로 이어지는지, 그리고 어떤 데이터나 통계를 활용하는지에 대한 이해 하고자 한다.
Optimizer의 기본 개념
아래는 전체적인 쿼리 실행 단계를 도식화한 예시이다.
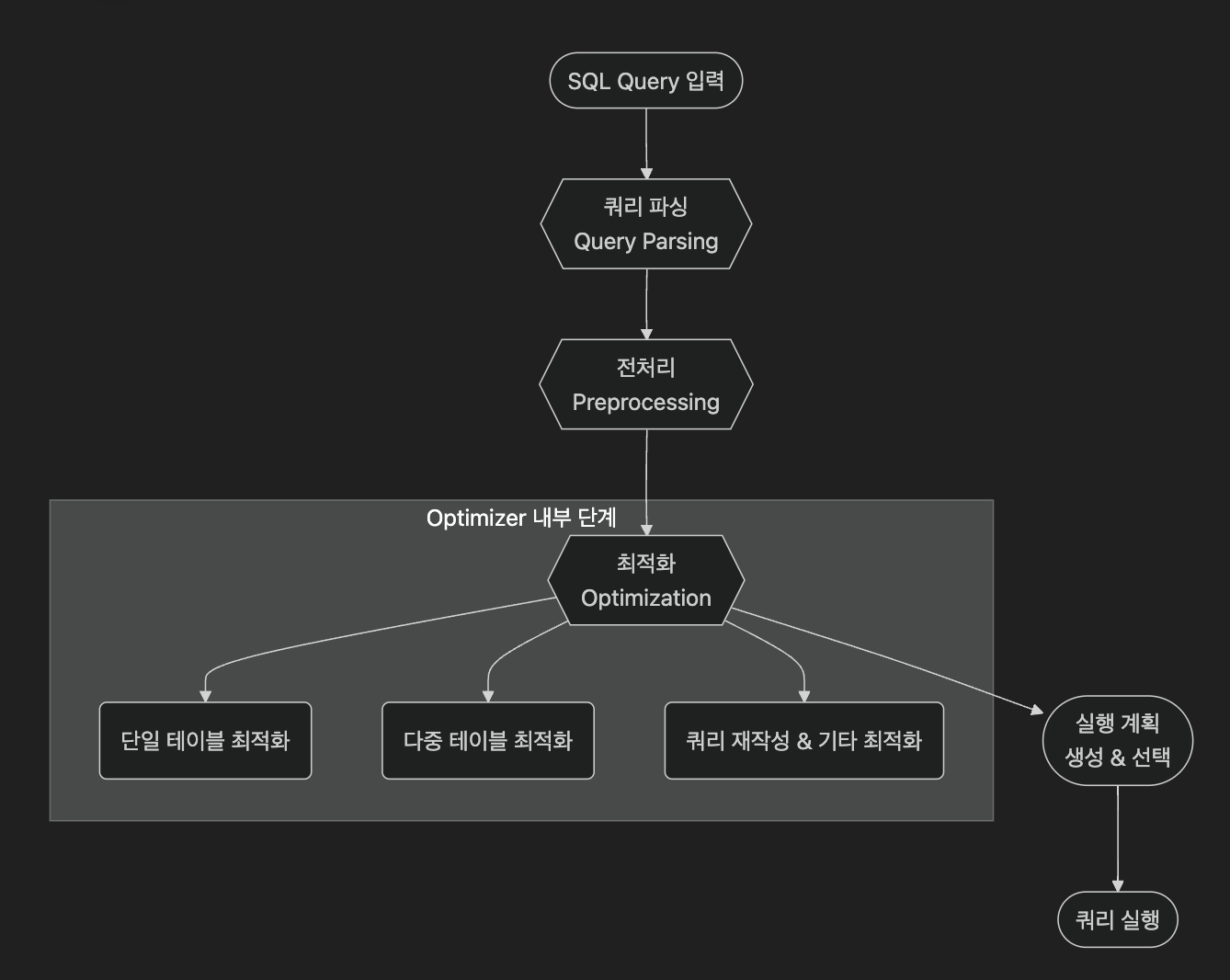
쿼리 파싱
SQL 문이 서버로 들어오면, MySQL SQL Parser는 쿼리 문법을 검사하고 내부 표현 구조(Parse Tree)로 변환한다.
이 과정에서 문법적으로나 구조적으로 쿼리에 오류가 없는지 확인한다.
쿼리 전처리
쿼리를 실행 계획으로 넘기기 전, MySQL은 View, Subquery, Referential Integrity 검사 등 다양한 전처리 작업을 수행한다.
이때 MySQL은 Parse Tree를 규격화하고, 쿼리에 따른 스키마 정보를 로드하며, 필요한 경우 쿼리 변환 및 단순화 작업을 병행한다.
쿼리 최적화
전처리된 쿼리가 Optimizer로 전달되면, Optimizer는 여러 가지 가능한 실행 경로를 검토하여 예상 비용이 가장 낮은 경로를 선택한다.
이를 위해 다양한 통계 정보와 규칙 기반 + 비용 기반 알고리즘을 혼합해 사용한다.
MySQL Optimizer의 구성 요소
비용 기반 최적화(Cost-based Optimization)
MySQL Optimizer는 데이터베이스 내부에 저장된 테이블 및 인덱스의 Cardinality, 통계 정보 등을 활용하여 각 선택지에 대한 비용을 계산한다.
- Cardinality: 테이블의 행 수, 인덱스 내에서 특정 값을 가지는 로우 수 등에 대한 추정치
- Statistics: 인덱스 분포, 데이터 분포, 테이블 크기, 평균 행 길이 등
Optimizer는 이러한 통계를 참고하여 ‘어떤 인덱스를 사용할 것인가’, ‘조인 순서를 어떻게 할 것인가’, ‘서브쿼리를 어떻게 풀어낼 것인가’를 결정하게 된다.
통계 정보의 중요성
MySQL Optimizer는 비용 기반으로 동작하기 위해 내부 통계 정보를 적극적으로 활용한다. 이때 통계 정보가 오래되면 부정확한 실행 계획이 세워질 수 있으므로, ANALYZE TABLE을 주기적으로 실행하거나 자동 수집 기능을 적절히 세팅해주는 것이 성능 최적화에 도움이 된다.
MRR(Multi-Range Read), ICP(Index Condition Pushdown)
- MRR(Multi-Range Read): 범위를 읽을 때 발생하는 Random Access를 최소화하기 위한 최적화 기술이다.
인덱스를 통해서 특정 범위의 레코드 위치를 한 번에 수집해 두고, 저장 엔진(MyISAM, InnoDB 등)이 연속된 디스크 I/O를 수행할 수 있게끔 정렬하는 기법이다. - ICP(Index Condition Pushdown): 인덱스로 필터링 가능한 조건을 최대한 먼저 수행하여 디스크 I/O를 줄이는 최적화 기술이다.
MySQL 5.6 이후 도입된 기능으로, 인덱스 스캔 과정에서 추가 조건을 적용해 불필요한 레코드 접근을 줄인다.
이러한 최적화 기능들도 Optimizer가 실행 계획을 세울 때 고려하는 요소이다.
쿼리 최적화 과정
단일 테이블 최적화
1. 인덱스 선택
단일 테이블에 대한 SELECT 쿼리의 경우, Optimizer는 사용 가능한 인덱스들을 확인하여 가장 효율적으로 검색할 수 있는 인덱스를 선택한다.
- Range scan
- Index scan
- Full table scan
- Index only scan (Covering Index)
2. 검색 조건의 단순화 및 인덱스 활용
WHERE 절에 있는 조건을 가능한 한 인덱스 조건으로 변환할 수 있는지 판단한다.
예를 들어 `WHERE column BETWEEN 10 AND 100` 같은 경우 Range Scan으로 처리할 수 있으며, 만약 `column`이 인덱스로 설정되어 있다면 빠른 검색이 가능하다 -> Covering Index
3. 프로젝션 최적화
필요한 컬럼이 인덱스에 모두 포함되어 있다면, 실제 테이블 데이터(클러스터드 인덱스나 데이터 페이지)를 읽지 않고도 결과를 반환할 수 있는 Covering Index 전략이 사용된다.
이를 통해 불필요한 I/O를 방지하여 DB에 대한 부하를 최소화할 수 있다.
다중 테이블 최적화
조인 순서 결정
MySQL Optimizer는 여러 테이블을 조인할 때, 각각의 테이블에 대하여 접근 방법을 결정하고, 테이블의 조인 순서를 정해야 한다.
- 가능한 조인 순서가 많을 경우, 모든 경우의 수를 완전 탐색할 수도 있지만, 테이블이 많아지면 매우 비효율적이다.
Nested Loop Join, Block Nested Loop Join
MySQL은 대체로 Nested Loop Join 기법을 사용한다. 내부적으로는 MRR과 같은 기법을 활용하여 조인 시 발생할 수 있는 무작위 접근을 줄이도록 한다.
- Index Nested Loop Join: 조인 컬럼에 인덱스가 있으면 outer loop에서 건네준 값으로 빠르게 내부 테이블을 찾아볼 수 있다.
- Block Nested Loop: 내부 테이블의 데이터를 일시적으로 블록 단위로 가져와서, 외부 테이블의 각 로우와 매칭할 때의 비용을 감소시키는 기법이다.
Semi-Join 및 Subquery 최적화
서브쿼리를 사용할 때, MySQL 5.6부터는 Semi-Join 전략을 통해 서브쿼리를 최적화한다. `EXISTS`, `IN` 서브쿼리 등을 외부 조인으로 변환하거나, FirstMatch 전략 등을 사용하여 전체 결과를 다 읽지 않고도 조건 충족 여부를 빠르게 확인할 수 있다.
조인 버퍼
인덱스가 없는 조인 칼럼으로 조인할 때, MySQL은 조인 버퍼를 사용하여 임시로 데이터를 저장하고, 그 버퍼를 통해 상대 테이블을 스캔하는 식으로 조인 비용을 최소화한다.
쿼리 재작성 및 기타 최적화
서브쿼리 Unnesting
MySQL은 종종 서브쿼리 Unnesting 기법을 사용하여 쿼리를 재작성한다. 예를 들어 `WHERE column IN (SELECT...)`처럼 작성된 쿼리는 내부적으로 조인 형태로 변환될 수 있으며, 이때 성능이 개선될 수 있다.
프로젝션 단순화
사용되지 않는 컬럼이나, 불필요한 중간 표현을 제거하는 과정을 거쳐 실제로 필요한 칼럼만 처리하도록 한다.
Distinct Optimization
`SELECT DISTINCT` 구문에서, 인덱스를 이용해 미리 중복 제거를 수행할 수 있는지(Loose Index Scan) 확인하고 최적화한다.
Group By 최적화
`GROUP BY` 구문이 있을 경우, 인덱스를 통한 그룹화가 가능한지 판단한다.
인덱스가 적절히 구성되어 있으면 MySQL은 임시 테이블 사용 없이 바로 그룹화 작업을 처리할 수 있다.
'Database' 카테고리의 다른 글
| MySQL 인덱스 탐색 원리와 LIKE 검색의 인덱스 활용 (0) | 2025.03.01 |
|---|---|
| 정규화(Normalization)란? (0) | 2024.06.06 |
| MVCC(Multi-Version Concurrency Control) 개념 (1) | 2024.06.04 |
| Connection을 미리 생성하는 이유 (0) | 2024.05.21 |
| [E-commerce] 캐시를 통한 애플리케이션 성능 개선 (1) | 2024.05.10 |