기존 KiCK OFF 프로젝트에 Redis를 적용하기 위해 Spring Boot에 Redis를 적용하는 방법을 간단한 프로젝트를 만들어서 공부해 보았다.
Redis 설정
build.gradle
우선 build.gradle에 redis를 사용하기 위해 의존성을 추가하고 빌드를 해준다.
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
Redis 사용을 위한 Config 클래스 설정
@Configuration
@EnableRedisRepositories
public class RedisConfig {
@Value("${spring.redis.host}")
private String redisHost;
@Value("${spring.redis.port}")
private int redisPort;
@Bean
public RedisConnectionFactory redisConnectionFactory() {
return new LettuceConnectionFactory(redisHost, redisPort);
}
@Bean
public RedisTemplate<String, Object> redisTemplate() {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory());
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new StringRedisSerializer());
// Hash를 사용할 경우 Serializer
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new StringRedisSerializer());
return redisTemplate;
}
}이후 redis를 사용하기 위해 Bean을 등록해준다.
그리고 redis를 Repository를 사용하는 방법과 Template를 사용하는 방법이 있는데 이번 프로젝트에서는 Repository를 사용할 예정이라 @EnableRedisRepositories 어노테이션 추가해준다.
그리고 Java의 Redis 클라이언트에는 Jedis와 Lettuce 두가지 종류가 존재한다.
이번에는 Lettuce를 사용할 예정이라 LettuceConnectionFactory를 생성해서 반환해준다.
위에서 setKeySerializer, setValueSerializer 설정해주는 이유는 Redis에 저장된 binary형태의 데이터를 String으로 변환시켜서 눈으로 확인하기 위함이다. (redis-cli를 통해서 binary 형태의 데이터를 직접 확인할 수 있다.)
redis에 데이터가 binary형태로 저장되는 이유는 Spring Data Redis는 기본 직렬화 방식이 JdkSerializationRedisSerializer이기 때문이다. 그래서 RedisTemplate는 객체를 자동으로 직렬화, 역직렬화 하여 binary 데이터를 redis에 저장을 한다.
redis-cli를 통해서 post 객체를 확인하면 아래와 같이 확인할 수 있다.

Jedis와 Lettuce의 성능 비교글
https://jojoldu.tistory.com/418
Jedis 보다 Lettuce 를 쓰자
Java의 Redis Client는 크게 2가지가 있습니다. Jedis Lettuce 둘 모두 몇천개의 Star를 가질만큼 유명한 오픈소스입니다. 이번 시간에는 둘 중 어떤것을 사용해야할지에 대해 성능 테스트 결과를 공유하
jojoldu.tistory.com
RedisRepository를 사용해 저장하기
Post(Entity) 클래스
@RedisHash(value = "post")
public class Post {
@Id
private Long id;
private String title;
private String content;
public Post(Long id, String title, String content) {
this.id = id;
this.title = title;
this.content = content;
}
// getter ...
}@RedisHash : Post를 Entity로 사용하기 위해 어노테이션을 추가해주고 이름을 설정한다.
여기서 설정한 post가 redis의 Entity라는 것을 나타내고, key의 prefix를 결정한다. ex "post:"
@ID : "post:{id}" 여기서 id 위치에 자동으로 생성되어 들어가는 값을 설정해준다. 즉 id가 key값이 된다고 생각하자. import할때 jpa의 id를 import하지 않도록 주의해야 한다.
import org.springframework.data.annotation.Id; O
import jakarta.persistence.Id; X
PostRepository 클래스
public interface PostRepository extends CrudRepository<Post, Long> {
}
이후 JpaRepository처럼 CrudRepository를 상속받은 Repository를 생성하고 test 클래스에서 post 객체를 redis에 저장해보자.
Save Test
@SpringBootTest
class RedisTest {
@Autowired
private PostRepository postRepository;
@Test
void save() {
Post post = new Post(1L, "title", "content");
postRepository.save(post);
Post findPost = postRepository.findById(post.getId()).get();
assertThat(findPost.getTitle()).isEqualTo("title");
}
}
위에 test클래스 처럼 post를 저장하고 redis-cli에서 key * 명령어를 통해 모든 키를 조회해보면 post가 저장된걸 아래와 같이 확인할 수 있다.

hgetall post:1 명령어를 통해 Post(1L, "title", "content")가 저장되었는지 확인을 해보면 아래와 같이 확인할 수 있다.
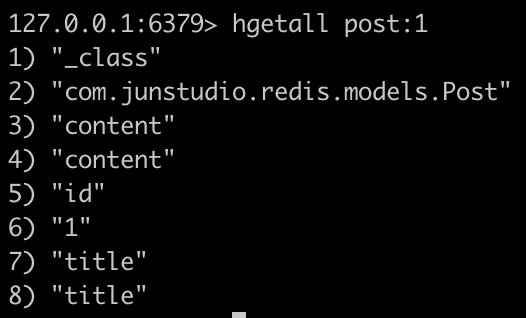
그런데 content랑 title이 두번 찍히는걸 볼 수 있는데 그 이유는 정확히 파악하지 못했다..
다음에는 DB에 자주 접근해 가져오는 데이터를 Redis의 Cache 기능을 활용해 데이터를 가져오는 시간을 줄여 성능을 개선해보자.
Reference
https://docs.spring.io/spring-data/data-redis/docs/current/reference/html/#reference
'Database' 카테고리의 다른 글
| [E-commerce] 캐시를 통한 애플리케이션 성능 개선 (1) | 2024.05.10 |
|---|---|
| [E-commerce] 쿼리 분석 및 인덱스 설계를 통한 성능 개선 (0) | 2024.05.10 |
| 함수적 종속성 (FD, Functional Dependency) (0) | 2024.04.14 |
| [OpenSearch] OpenSearchClient와 OpenSearch Query DSL 이용하기 (0) | 2023.07.29 |
| [Redis] Redis 캐시(Cache)를 적용해 조회 성능 개선하기 (0) | 2023.02.16 |